
Update May 2, 2025: As of release v0.78.0, Terragrunt Stacks is now generally available. You are now encouraged to start using Terragrunt Stacks in production!
In the Road to Terragrunt 1.0 blog post, we officially introduced the concept of Terragrunt stacks, a powerful new way to simplify your Terragrunt code and reduce repetition by defining common patterns as a single, reusable entity.
In this post, we’d like to provide a deep-dive on Terragrunt Stacks, and give some more background on why they matter.
Why Build Terragrunt Stacks?
It all starts by recognizing the central organizing principle of Terragrunt, which is that infrastructure becomes manageable and scalable when you work with small, reliable units of infrastructure.
In Terragrunt, you create a unit by creating a directory, and placing a terragrunt.hcl file within it. This is a powerful abstraction because it makes reasoning about your infrastructure very simple. For every unit (directory with a terragrunt.hcl file in it), you have a unique piece of infrastructure you can work with in isolation. Terragrunt users typically take full advantage of this and get really granular with infrastructure management by gradually reducing the size of their units.
Small units of infrastructure gives you all kinds of benefits, including:
- Containment — units are contained, and can be updated in isolation without putting all of your infrastructure at risk (low blast radius).
- Clean Updates— units can be updated in atomic version bumps without digging through messy code changes relating to module internals.
- Consistency — units intentionally expose an interface that aims to make them as reproducible as possible across environments, only allowing you to configure instances of infrastructure patterns, rather than defining them directly.
These benefits are great, and they give users the ability to manage really large infrastructure estates in a very efficient manner.
For users with particularly large infrastructure estates, however, one piece of feedback kept coming up. Users kept sharing that they didn’t want to have to manage the sprawl of identical (or almost identical) sets of units across similar patterns of infrastructure deployment.
For example, when defining a new environment, a new single-tenant customer or a new cloud region, you typically want to reproduce multiple interrelated units with slight variation in that new environment, for that new customer or in that new cloud region. Due to the design of Terragrunt units, you may only need to change a single file indicating the name of the environment, the customer or cloud region.
Until now, the process for handling this use case was to copy and paste a directory tree of units, then adjust some shared configuration they all referenced (or “copy, paste, season to taste”). What if there was a way to deploy a new stack of units with a single file, however?
With Terragrunt Stacks, we aim to handle this use case in a first-class way. So let’s dive in!
What are Terragrunt Stacks?
Terragrunt Stacks are a new way to organize and manage infrastructure using Terragrunt. They introduce a layer of abstraction above Terragrunt Units (individual terragrunt.hcl files), using a new configuration file named terragrunt.stack.hcl. These files allow you to define and manage collections of reusable infrastructure Units within a single Stack.

Since very early on in Terragrunt’s history, the name used for a collection of units has been a stack, but there has been no formal construct to conveniently generate or manage them. We’ve taken the lessons learned from managing infrastructure at scale to provide a new primitive that is fully backwards compatible with how users use Terragrunt today.
Here’s an example of what that new terragrunt.stack.hcl file looks like:
# terragrunt.stack.hcl
unit "vpc" {
source = "github.com/acme/terragrunt-units.git//units/vpc?ref=v1.2.3"
path = "vpc"
values = {
environment = "prod"
}
}
stack "service" {
source = "github.com/acme/terragrunt-stacks.git//stacks/stateful-service?ref=v1.2.3"
path = "service"
values = {
environment = "prod"
}
}
This blog discusses the thought process of their design, how to think about them and how to work with them. If you want to skip straight to reading about this syntax, you can skip to Dynamic Stacks at the end of the post.
Building Up to a Stack
Stacks are an abstraction, and as such, it helps to go through the layers of abstractions that exist in Terragrunt (and OpenTofu/Terraform beneath it), so you get a sense of what we’re building up to here.
OpenTofu/Terraform resource
This is the bottom of our abstraction.
A resource is something provisioned via Create, Read, Update and Destroy (CRUD) operations, and OpenTofu/Terraform handle the lifecycle of that resource. The underlying technology that handles these CRUD operations are OpenTofu/Terraform providers.
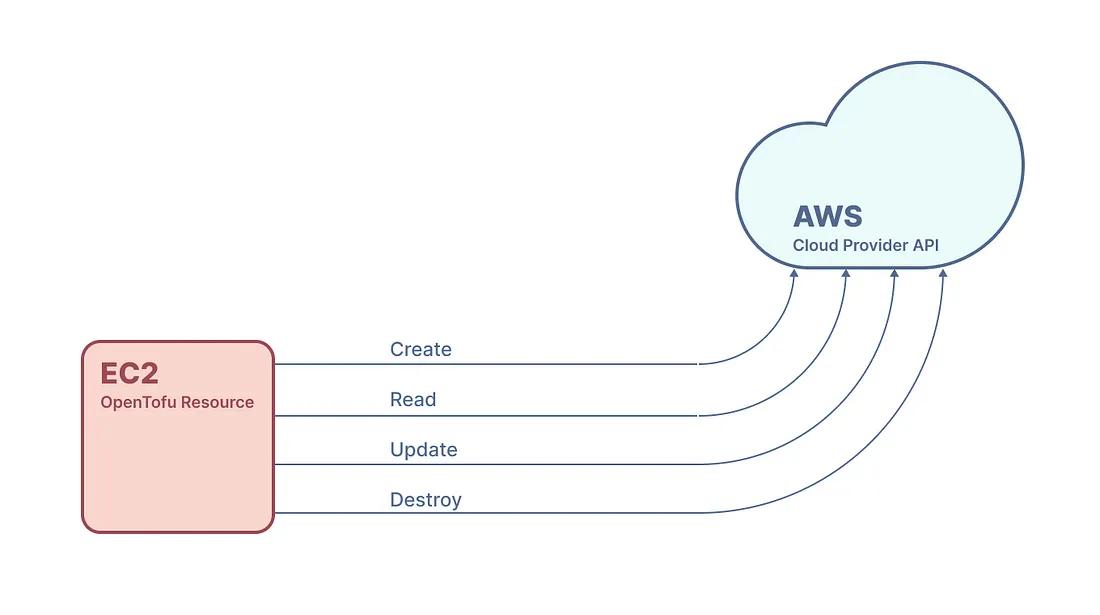
For example, the AWS provider handles all the CRUD operations for managing an EC2 virtual machine in AWS as a resource.
You’d define one like this:
resource "aws_instance" "instance" {
ami = var.ami
instance_type = var.instance_type
subnet_id = var.subnet_id
security_groups = var.security_groups
}
As a consumer of a resource, you avoid taking on the cognitive burden of interfacing with APIs for managing the lifecycle of a resource you want to provision. You tell OpenTofu/Terraform that you want something to exist (or not exist) in a given state, and the resource makes it so.
OpenTofu/Terraform module
Moving up a layer of abstraction is the OpenTofu/Terraform module.
This is a collection of one or more resources in a container defining a pattern of infrastructure. Good modules are typically small, and focused. They abstract away the implementation details of provisioning resources so that a convenient interface is made available to instantiate them.

For example, a module that provisions an EC2 instance may only expose required variables for the VPC subnet where the instance should be provisioned, security groups for the instance and the instance type to use, and exposes outputs that are useful from that instance.
You might provision a module that provisioned the resource defined earlier with OpenTofu/Terraform code like this:
module "instance" {
source = "github.com/acme/infrastructure-modules//modules/ec2?refv1.2.3"
instance_type = var.instance_type
subnet_id = var.subnet_id
security_groups = var.security_groups
}
Note that in this example, we’ve intentionally dropped the ami variable for the module. The module author here has theoretically implemented something using a data source to lookup a good AMI.
As a consumer of the module, you have avoided taking on the cognitive burden of worrying about how you provision an EC2 instance, and how the plumbing works to put it together. Because the module authors have taken care of that, you provide the business logic by setting inputs, and the module handles the rest. Moreover, the inputs have been intentionally constrained to make it easier for you to reliably get the right thing provisioned. The module authors can also curate the information that is most likely to be relevant to you in the form of outputs and exposed those selectively for you.
Terragrunt units
Moving up another layer of abstraction is the Terragrunt unit.
This is a construct used to provision a single instance of an OpenTofu/Terraform module, largely constraining you to set inputs to the module, extract outputs from it and handle other concerns relating to getting that module provisioned. Because you are heavily encouraged to focus on instantiating production-ready, well tested modules, units maximize reproducibility. The vast majority of Terragrunt usage allows for units to be copied to create new infrastructure with very little need for additional configuration.

They also allow you to focus on other responsibilities involved in provisioning infrastructure that don’t have to do with defining infrastructure patterns. What needs to happen whenever this unit is provisioned? What other infrastructure has to be updated before this unit? What should happen when this unit fails to update?
For example, the production server for a product may be a unit that provisions a Gruntwork Library module for EC2 instances with a dependency on the VPC unit where it is provisioned.
You might define that with Terragrunt code that looks like this slightly modified terragrunt.hcl file from the Terragrunt Getting Started Guide:
terraform {
source = "tfr:///terraform-aws-modules/ec2-instance/aws?version=5.7.1"
}
dependency "vpc" {
config_path = "../vpc"
}
inputs = {
name = "stacks-blog-instance"
instance_type = "t4g.medium"
subnet_id = dependency.vpc.outputs.private_subnets[0]
vpc_security_group_ids = ["sg-12345678"]
}
As a unit author, you avoid taking on the cognitive burden of what exactly a module does. You focus on configuring it to have the inputs it needs, and worry about what it means to have it running in production, in dev, across regions, etc. Modules become generic patterns of infrastructure that are easy to reproduce, and you focus on getting that infrastructure running.
Terragrunt stacks
Moving up the final layer of abstraction is the Terragrunt stack.
Stacks are a construct for provisioning one or more units of infrastructure. Units in a stack are able to pass data between them using dependencies, and are provisioned and de-provisioned intelligently, leveraging their dependency relationship within a Directed Acyclic Graph (DAG) to determine which units to update first.

They allow you to retain all the benefits of units (e.g. hermiticity, atomicity and reproducibility), while giving you a higher level construct for interacting with them as a collective.
For example, the “dev” stack for a product may include an EC2 unit, a VPC unit, a DB unit, etc. When you want to provision that same set of infrastructure again, you can produce a “prod” stack that has all the same units, and allows you all the same granular control over them. You can work on each stack independently, meaning that the updates you make in the dev stack can’t impact the work you do in the production stack.
.
├── dev
│ ├── db
│ │ └── terragrunt.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
├── prod
│ ├── db
│ │ └── terragrunt.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
└── stage
├── db
│ └── terragrunt.hcl
├── ec2
│ └── terragrunt.hcl
└── vpc
└── terragrunt.hcl

On the road to 1.0, we’re introducing a special construct for making it really easy to provision this construct, the terragrunt.stack.hcl file. Instead of seeing all the nuts and bolts of your stack in your filesystem, you’ll instead see one file where the collection of units would normally be, representing the entire stack.
As a stack author, you avoid taking on the cognitive burden of what exactly is managed in a stack. You focus instead on the overall stack of infrastructure, which you manage as a collective, and can, at any moment, work with the individual units in your stack in isolation instead.
Benefits of the terragrunt.stack.hcl file
Terragrunt Stacks allow you to:
- Reduce Repetition: Consolidate many
terragrunt.hclfiles into a singleterragrunt.stack.hclfile, streamlining your codebase. - Improve Scalability: Propagate updates across infrastructure of any size without making repeated edits in multiple files.
How Terragrunt Stacks Work
The key innovation in Terragrunt Stacks is the introduction of the new terragrunt.stack.hcl file. Let’s look at the simplest possible example for that file:
# terragrunt.stack.hcl
unit "name" {
source = "path/to/unit/definition"
path = "path/to/unit/generation"
}
This is a trivial (and somewhat pointless) stack that manages a single unit.
The source attribute tells Terragrunt where to find the definition of a unit, and the path tells Terragrunt where to put a copy of that unit. That’s it!
The mechanics for this are pretty simple. The source attribute of the unit configuration block supports the same go-getter URL that the terraform configuration block does, allowing you to tell Terragrunt where the definition for a unit is (in your filesystem, in a git repository, somewhere on the internet, wherever), and have that unit copied somewhere in your filesystem.
By default, the path attribute is actually a suffix for the destination where your units will end up. They are nested into a .terragrunt-stack directory, which you can safely add to your .gitignore files so that they don’t bloat your repositories and are dynamically generated on demand, when you need them. You will also be able to opt-out of this behavior for the sake of backwards compatibility, which will be discussed at length later.
For most Terragrunt users, this alone will allow for significant code deduplication. Any time you have identical copies of a unit, you can define it once somewhere, then reference it as many times as you need them replicated instead of copying terragrunt.hcl files.
What’s more, nothing in your terragrunt.hcl files has to change. The design of terragrunt.stack.hcl files has been purposely designed to be fully backwards compatible with how users author stacks today.
We have more planned for terragrunt.stack.hcl files, however, that will give you access to more capabilities than you can get with what terragrunt.hcl files do today. We’ll get to that later.
Finally, we introduce a new subcommand, terragrunt stack that specifically works with these new terragrunt.stack.hcl files. Over time, these files will be handled transparently by other commands, but we’ll continue to support a dedicated command for working with individual stacks, as a first class citizen in the CLI.
Key Concepts
In a moment, we’ll walk through a hello world of Terragrunt Stacks, but first, let’s recap the core concepts:
- Resources: Individual things managed by OpenTofu/Terraform, and provisioned using providers.
- Modules: The familiar old collection of OpenTofu or Terraform files ending in
.tfthat can be provisioned using Terragrunt Units. - Units: Individual instances of OpenTofu/Terraform modules that have their own state, defined using
terragrunt.hclfiles. - Stacks: Collections of related Units, defined using
terragrunt.stack.hclfiles.
Getting Started with Stacks
As of today, Stacks are not yet publicly available (see the latest status in our public RFC), but the following will be the basic hello world experience for using Stacks:
1. Create a new git repository to test out Stacks.
$ mkdir testing-stacks
$ cd testing-stacks
$ git init
2. Create or identify an OpenTofu/Terraform module you want to repeatedly provision.
# modules/null/main.tf
resource "null_resource" "example" {
provisioner "local-exec" {
command = "echo ${var.message}"
}
}
variable "message" {
type = string
}
To avoid requiring AWS access, this example uses the typical null_resource resource, but feel free to replace this with whatever resource you frequently need provisioned.
3. Create a Terragrunt unit to provision that module.
# units/null-with-message/terragrunt.hcl
terraform {
source = "${get_repo_root()}/modules/null"
}
inputs = {
message = "Provisioned in directory: ${basename(get_terragrunt_dir())}"
}
Note the use of the built-in get_repo_root function in source. This allows all files to be referenced relative to the root of the git repository created in step 1.
In addition, take a look at the message input. It’s being defined using a combination of Terragrunt HCL functions to leverage its location in the filesystem as part of how the infrastructure is defined.
This is a very common pattern in Terragrunt usage today. Units frequently lookup data that they need to configure a module using their position in the filesystem. That same pattern will translate directly to stack usage.
4. Create a stack that instantiates multiple of those units.
# live/example-stack/terragrunt.stack.hcl
unit "first_null" {
source = "${get_repo_root()}/units/null-with-message"
path = "first-null"
}
unit "second_null" {
source = "${get_repo_root()}/units/null-with-message"
path = "second-null"
}
Note that, again, the get_repo_root function is being used to reference the unit definitions relative to the root of the git repository.
The terragrunt.stack.hcl file here is relatively simple: it simply generates units at particular filesystem paths.
5. Run terragrunt stack generate to see the .terragrunt-stack generated.
$ cd live
$ terragrunt stack generate
$ tree .terragrunt-stack
.terragrunt-stack
├── first-null
│ └── terragrunt.hcl
└── second-null
└── terragrunt.hcl
6. Run terragrunt stack apply to apply the Stack.
$ terragrunt stack apply
If you’re familiar with Terragrunt, this is equivalent to simply running the following within the .terragrunt-stack directory:
# .terragrunt-stack
$ terragrunt run-all apply
No Required Changes in terragrunt.hcl
In the simple example above, the same unit configuration is repeated multiple times, and information gleaned from the filesystem determined inputs for the units (the name of the directory that the unit was generated into).
This is often enough variability when instantiating stacks. Generally, two infrastructure stacks that differ only by the names of the resources they provision are going to reproduce behavior far more faithfully.
In the real world, however, things can get messy. Different instances of the same stack might require different resources (like larger VMs in production than in development), or use different, hard to predict values (like database connection strings).
As an example, let’s look at what a user would do today with Terragrunt to have conveniently reproducible infrastructure, and how that maps to a world with terragrunt.stack.hcl files:
.
├── root.hcl
└── live
├── dev
│ ├── environment.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ ├── rds
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
└── prod
├── environment.hcl
├── ec2
│ └── terragrunt.hcl
├── rds
│ └── terragrunt.hcl
└── vpc
└── terragrunt.hcl
This is a pretty typical file structure for someone writing Terragrunt configurations.
The root.hcl file at the root of the repository has all the shared configurations to be included by other terragrunt.hcl files.
The files not named terragrunt.hcl are typically shared configuration files that are included by units. These typically contain the configuration that’s used to make the stacks (dev, prod, etc) behave differently.
The terragrunt.hcl files in units like ec2, rds, vpc are typically fairly minimal, mostly just including shared configuration. These files largely function as filesystem indicators that some set of infrastructure will be provisioned with independent state. The state for these units in the backend (e.g. s3) will have keys determined by the relative filesystem path from the root.hcl file to a given unit. When your working directory is set to this unit, you can work with it in complete isolation.
The stacks like dev and prod represent different environments with almost identical infrastructure. They provision independent resources with independent state, but require files to be present on the filesystem to retain the advantages mentioned above.
Let’s take a look at some critical portions of these files to see how users typically define them to reach the goal of achieving DRY (Don’t Repeat Yourself) infrastructure.
root.hcl
generate "provider" {
path = "provider.tf"
if_exists = "overwrite_terragrunt"
contents = <<EOF
provider "aws" {
region = "us-east-1"
}
EOF
}
remote_state {
backend = "s3"
config = {
bucket = "acme-bucket-name-us-east-1"
key = "${path_relative_to_include()}/tofu.tfstate"
region = "us-east-1"
}
generate = {
path = "backend.tf"
if_exists = "overwrite_terragrunt"
}
}
In this example, all that is defined in the root.hcl configuration is a generate block, and a remote_state block. These two ensure that every unit of infrastructure automatically generates configurations for:
- Configuring the OpenTofu AWS provider.
- Configuring the backend state where OpenTofu state will be stored.
Configuration like this typically needs to be present in every production OpenTofu project, so it’s safe to assume that every unit will want to include that.
In addition, there’s some special configuration that will determine the key where state is stored in the backend:
"${path_relative_to_include()}/tofu.tfstate"
This is what makes the location of units in the filesystem relevant for determining where state is stored.
e.g.
The unit located at live/dev/ec2 will have its state stored in:
s3://acme-bucket-name-us-east-1/live/dev/ec2/tofu.tfstate
Extra Includes
The extra included files outside of the root terragrunt.hcl file are typically only relevant to a particular scope of infrastructure. In this example, the environment.hcl file located under live/dev only contains configurations relevant to that environment. One can read this file and know all the shared configuration that will be utilized by the infrastructure provisioned in directories beneath it in the filesystem.
For example, a user might want to have the following environment.hcl under live/dev:
inputs = {
instance_type = "t3.small"
}
And they may want to have different configurations under live/prod:
inputs = {
instance_type = "t3.large"
}
A user reading this environment.hcl could then theoretically have a full understanding of how the two environments differ, assuming all differences in configuration were stored in these files.
We’ll share a different approach to handling this kind of shared configuration when we explore how terragrunt.stack.hcl files work.
Units
To round out this example before explaining how terragrunt.stack.hcl files come into the picture (I promise, we’re almost there), consider what would be in the live/dev/ec2/terragrunt.hcl file. It might be something like this:
terraform {
source = "github.com/acme/terraform-aws-ec2.git//modules/instance?ref=v1.2.3"
}
include "root" {
path = find_in_parent_folders("root.hcl")
}
include "environment" {
path = find_in_parent_folders("environment.hcl")
}
dependency "vpc" {
config_path = "../vpc"
}
inputs = {
vpc_id = dependency.vpc.outputs.id
}
The unit definition takes advantage of the re-usable parts of Terragrunt configuration defined elsewhere, and defines how the unit relates to adjacent configuration (vpc). Defining this dependency also instructs Terragrunt to plan and apply configurations following the Directed Acyclic Graph (DAG) by always ensuring that the vpc unit is updated before the ec2 unit, resulting in the proper ordering of updates.
This is one of the most important features of Terragrunt, as it allows for the best of both worlds: an integrated collection of units that are aware of each other and coordinate nicely, while also providing tooling to work with units in complete isolation.
Using terragrunt.stack.hcl
Note that the file live/dev/ec2/terragrunt.hcl is almost definitely going to be almost entirely identical to the file live/prod/ec2/terragrunt.hcl.
This is the situation many users find themselves in today. They have identical terragrunt.hcl files placed strategically throughout their codebase to indicate where infrastructure state is going to stored, and how it relates to other infrastructure.
Today, most users wanting to introduce a new qa environment would do so by copying the live/prod directory, paste it as live/qa, then edit the environment.hcl file if necessary to address any difference in configuration.
With the release of terragrunt.stack.hcl support, however, they’ll instead be able to introduce the new stack like this:
.
├── terragrunt.hcl
└── live
├── dev
│ ├── environment.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ ├── rds
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
├── prod
│ ├── environment.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ ├── rds
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
└── qa
├── environment.hcl
└── terragrunt.stack.hcl
With a terragrunt.stack.hcl that look like the following:
unit "instance" {
source = "github.com/acme/terragrunt-units.git//units/ec2/instance?ref=v1.2.3"
path = "ec2"
}
unit "db" {
source = "github.com/acme/terragrunt-units.git//units/rds/db?ref=v1.2.3"
path = "rds"
}
unit "vpc" {
source = "github.com/acme/terragrunt-units.git//units/vpc?ref=v1.2.3"
path = "vpc"
}
Where the terragrunt.hcl file located in the github.com/acme/terragrunt-units repository under the directory units/ec2/instance is the exact same terragrunt.hcl file you saw before:
terraform {
source = "github.com/acme/terraform-aws-ec2.git//modules/instance?ref=v1.2.3"
}
include "root" {
path = find_in_parent_folders("root.hcl")
}
include "environment" {
path = find_in_parent_folders("environment.hcl")
}
dependency "vpc" {
config_path = "../vpc"
}
inputs = {
vpc_id = dependency.vpc.outputs.id
}
When using any terragrunt stack command, the stack will be automatically generated into the filesystem under a .terragrunt-stack directory, like so:
.
├── root.hcl
└── live
├── dev
│ ├── environment.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ ├── rds
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
├── prod
│ ├── environment.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ ├── rds
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
└── qa
├── environment.hcl
├── terragrunt.stack.hcl
└── .terragrunt-stack
├── ec2
│ └── terragrunt.hcl
├── rds
│ └── terragrunt.hcl
└── vpc
└── terragrunt.hcl
All the includes still work as they did before, fetching shared configuration from common sources, and dependency references still work as they did before.
This means that adoption of Stacks requires learning zero new syntax for terragrunt.hcl files.
You can simply copy the configurations you are currently using for terragrunt.hcl files, store them somewhere you are going to reference later, then have them rendered dynamically on demand. There is no new syntax you have to use for passing extra configurations to units, and everything you currently use in terragrunt.hcl files will work in stacks.
In-fact, if you wanted to, you could navigate to the live/qa/.terragrunt-stack/ec2 directory, and run terragrunt plan/apply as if it wasn’t part of a stack, and it would work just like it did before.
This was an important design decision for us, as we want to make sure that you are able to adopt stacks gradually over time, and can continue to use all the code you’ve been using while taking advantage of terragrunt.stack.hcl files for updated infrastructure. We recognize that writing Infrastructure as Code (IaC) is not free, and we don’t want you to feel like you have to toss out all the code you’ve written so far to use this new feature.
This includes code for Continuous Integration (CI). If your CI isn’t aware of how stacks work, no problem! Simply commit the files located under .terragrunt-stack, and as far as your CI tooling is concerned, it is just another terragrunt.hcl file. For any tooling that is aware of how stacks work (like Gruntwork Pipelines will be), you can gitignore .terragrunt-stack directories, and leave your repositories uncluttered by repeated terragrunt.hcl files.
Nested Stacks
In addition to supporting unit {} configuration blocks, stacks also support stack {} configuration blocks which instantiate other stacks instead of units. This is a useful abstraction, as it allows users to decide the exact level of re-use that makes sense for them.

For example, say you wanted to have a single versioned reference to the stack defined above integrating an ec2 and rds unit, but not the VPC. You could do that like so:
unit "vpc" {
source = "github.com/acme/terragrunt-units.git//units/vpc?ref=v1.2.3"
path = "vpc"
}
stack "stateful_service" {
source = "github.com/acme/terragrunt-stacks.git//stacks/stateful-service?ref=v1.2.3"
path = "stateful-service"
}
The resulting filesystem from a terragrunt stack command would look more like this within the live/qa directory:
.
├── environment.hcl
├── terragrunt.stack.hcl
└── .terragrunt-stack
├── stateful-service
│ └── .terragrunt-stack
│ ├── ec2
│ │ └── terragrunt.hcl
│ └── rds
│ └── terragrunt.hcl
└── vpc
└── terragrunt.hcl
The source URL for the stateful-service stack could be updated on one cadence relevant to rds and ec2 units, and the vpc unit source URL can be updated on a different cadence.
A team deploying multiple instances of a stack containing an EC2 instance and an RDS database in the same VPC might also prefer this pattern, as it would allow them to encapsulate that stack as one reusable entity.
unit "vpc" {
source = "github.com/acme/terragrunt-units.git//units/vpc?ref=v1.2.3"
path = "vpc"
}
stack "stateful_service" {
source = "github.com/acme/terragrunt-stacks.git//stacks/stateful-service?ref=v1.2.3"
path = "stateful-service"
}
stack "another_stateful_service" {
source = "github.com/acme/terragrunt-stacks.git//stacks/stateful-service?ref=v1.2.3"
path = "another-stateful-service"
}
Maximizing Backwards Compatibility
Given that Terragrunt already supports one form of stacks (a directory tree of units), and users already have infrastructure estates, small and large, provisioned using Terragrunt, we’ve put a lot of thought into backwards compatibility.
For that reason, we’ve also designed a small additional feature, the hidden attribute, which you can use to back-port existing stacks into terragrunt.stack.hcl files.
For example, take the filesystem we discussed above:
.
├── root.hcl
└── live
├── dev
│ ├── environment.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ ├── rds
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
├── prod
│ ├── environment.hcl
│ ├── ec2
│ │ └── terragrunt.hcl
│ ├── rds
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
└── qa
├── environment.hcl
├── terragrunt.stack.hcl
└── .terragrunt-stack
├── ec2
│ └── terragrunt.hcl
├── rds
│ └── terragrunt.hcl
└── vpc
└── terragrunt.hcl
Over time, you might have changes to the ec2, rds and vpc unit configurations that you want to use consistently throughout your infrastructure estate. For all new stacks, this isn’t much of a problem. The terragrunt.stack.hcl file supports versioned references to unit configurations, and you can simply create new terragrunt.stack.hcl files that use the latest configurations.
A problem arises, however, when attempting to adjust the dev and prod stacks to use terragrunt.stack.hcl files. Recall that Terragrunt units take advantage of their relative positions in the filesystem to determine their path in state.
The live/dev/ec2 unit will have its state stored in:
s3://acme-bucket-name-us-east-1/live/dev/ec2/tofu.tfstate
Whereas the live/qa/.terragrunt-stack/ec2 unit will have its state stored in:
s3://acme-bucket-name-us-east-1/live/qa/.terragrunt-stack/ec2/tofu.tfstate
Having stack generation default to taking place within a hidden .terragrunt-stack directory is useful, as it allows users to ignore those directories in their git repositories, as relevant commands will automatically regenerate them.
A user adopting terragrunt.stack.hcl files will be able to do the following in order to work around the fact that they weren’t originally provisioned within a .terragrunt-stack directory:
# live/dev/terragrunt.stack.hcl
unit "instance" {
source = "github.com/acme/terragrunt-units.git//units/ec2/instance?ref=v1.2.3"
path = "ec2"
hidden = false
}
unit "db" {
source = "github.com/acme/terragrunt-units.git//units/rds/db?ref=v1.2.3"
path = "rds"
hidden = false
}
unit "vpc" {
source = "github.com/acme/terragrunt-units.git//units/vpc?ref=v1.2.3"
path = "vpc"
hidden = false
}
This results in stack generation that won’t place generated units in the hidden .terragrunt-stack directory, allowing users to migrate to terragrunt.stack.hcl files with no state movement at all.
Files committed to the git repository would then look more like this, with no required state movement:
.
├── root.hcl
├── dev
│ ├── environment.hcl
│ └── terragrunt.stack.hcl
├── prod
│ ├── environment.hcl
│ └── terragrunt.stack.hcl
└── stage
├── environment.hcl
└── terragrunt.stack.hcl
Dynamic Stacks
Finally, while you won’t be forced to learn or use anything new in your terragrunt.hcl files with the release of stacks, we’ve received feedback from the community that they want more out of the stacks design.
We take that feedback seriously, so today we’re announcing that we’ll be supporting configurations for allowing stacks to be configured dynamically by consumers when they’re instantiated using terragrunt.stack.hcl files.
e.g.
# terragrunt.stack.hcl
unit "vpc" {
source = "github.com/acme/terragrunt-units.git//units/vpc?ref=v1.2.3"
path = "vpc"
values = {
environment = "prod"
}
}
stack "service" {
source = "github.com/acme/terragrunt-stacks.git//stacks/stateful-service?ref=v1.2.3"
path = "service"
values = {
environment = "prod"
}
}
# github.com/acme/terragrunt-units.git//units/vpc?ref=v1.2.3
terraform {
source = "github.com/acme/terraform-aws-vpc.git//modules/vpc?ref=v1.2.3"
}
include "root" {
path = find_in_parent_folders("root.hcl")
}
dependency "vpc" {
config_path = "../vpc"
}
inputs = {
environment = unit.values.environment
}
# github.com/acme/terragrunt-stacks.git//stacks/stateful-service?ref=v1.2.3
unit "instance" {
source = "github.com/acme/terragrunt-units.git//units/ec2/instance?ref=v1.2.3"
path = "ec2"
values = {
environment = stack.values.environment
}
}
unit "db" {
source = "github.com/acme/terragrunt-units.git//units/rds/db?ref=v1.2.3"
path = "rds"
values = {
environment = stack.values.environment
}
}
Users authoring unit and stack configurations, specifically intending for them to be consumed by other stacks will automatically have access to special values (unit.values and stack.values), which terragrunt.stack.hcl file authors will be able to set when instantiating the stack. By using these values, you as the unit/stack author, also explicitly indicate what values you expect to be populated by a stack instantiating your configurations.
We’ve been discussing the merits of announcing the design for this feature early, as one of our core values at Gruntwork is incrementalism, and we do feel like users will be able to gain significant benefit from terragrunt.stack.hcl files without leveraging any new configurations in terragrunt.hcl files.
We initially intended to launch support for stacks without any new terragrunt.hcl configurations, and see how users used them before announcing any new terragrunt.hcl syntax. We also really liked the idea that terragrunt.hcl couldn’t use anything that was only valid in the context of a stack (the unit.values and stack.values values above will throw errors when used outside the context of a stack).
Another consideration is that we want to assure users that have a lot of terragrunt.hcl files that you do not need to rewrite them all! The features described here are purely opt-in for users that are starting new stacks, and want to avoid techniques using functions like find_in_parent_folders.
Ultimately, it was feedback from the community and internal prototyping that encouraged us to announce this design and commit to building it out before the release of 1.0. We think supporting it early will be in the best interest of the Terragrunt community, and make adoption as smooth as possible.
Read the RFC
To learn more about Stacks, including the full specification for how they work, and numerous examples, read RFC #3313. As always, feedback is welcome!
Release date
We just released the Alpha version of Terragrunt Stacks earlier today. As we do, per the Gruntwork way, we’ll gather community feedback, and iterate from there.
Because of this iterative process, we don’t have an exact release date, but we’ll share updates as we ship releases. Our tentative target for general availability is Q1 2025.
We don’t plan on building Stacks in a vacuum, so please share your feedback!
Closing thoughts
With Terragrunt Stacks, we expect to see a dramatic change in how Terragrunt codebases are authored. You will have a far greater degree of code reuse, and the ability to express infrastructure concisely.
Please share your feedback! We invite you to:
- Comment on this blog post
- Review and comment on the RFC
- 💬 Chat with me in our Discord Server
Special thanks to Eben Eliason, Josh Padnick and Zach Goldberg for their contributions in shaping this blog post. A special thank you to Eben for the gorgeous graphics used in this post. Make sure to give him a shout out in the comments!
Errata
An earlier version of this post used outdated syntax for unit and stack configuration blocks without labels.
e.g.
unit {
source = "path/to/unit/definition"
path = "path/to/unit/generation"
}
Instead of:
unit "name" {
source = "path/to/unit/definition"
path = "path/to/unit/generation"
}
This was an adjustment made early on during iteration in the RFC, but the change didn’t get reflected in the blog post until now.



- No-nonsense DevOps insights
- Expert guidance
- Latest trends on IaC, automation, and DevOps
- Real-world best practices


.png)
